
Bài viết này chia sẻ kinh nghiệm sử dụng Python để scrape dữ liệu từ NASA nhằm phục vụ mục đích nghiên cứu. Gần đây Hà Nội phải đối mặt với tình trạng bụi mịn cao (nồng độ PM 2.5 cao hơn mức cho phép) cùng với sương mù. Chúng ta có thể sử dụng dữ liệu NASA để có cái nhìn khách quan hơn về chất lượng không khí cho cả nước.
Chúng ta cần tiến hành các bước như sau:
- Bước 1: Lấy dữ liệu latitude
latvà longitudeloncủa từng vùng miền - Bước 2: Tìm database các chỉ số không khí
- Bước 3: Match hai cái lại với nhau.
Mục tiêu là làm sao tạo ra một cái bản đồ như thế này.

Geodata địa giới hành chính
Về địa giới hành chính, chúng ta sẽ lấy từ GADM (Global ADMinistrative layer)
https://gadm.org/download_country.html
Chọn vietnam và chọn level1. Level 1 là cấp độ tỉnh/thành, trong bài viết này là vừa đủ. Nếu muốn cấp độ thành phố/thị xã thì các bạn chọn level 2. Sau đó tải về và chạy dòng code sau (Dòng cuối sẽ plot biểu đồ đất nước).
import geopandas as gpd
geojson_file = 'gadm41_VNM_1.json'
# Read in the GeoJSON file
gdata = gpd.read_file(geojson_file)
# Plot the GeoDataFrame
gdata.plot()
Nếu các bạn print(gdata) thì sẽ thấy đủ 63 tỉnh thành. Tên được quy định ở column NAME_1 đi kèm với geometry của nó. Cái geometry thì là một cái tuples chứa địa giới theo kinh độ và vĩ độ của tỉnh.
NAME_1 geometry
0 AnGiang MULTIPOLYGON (((105.54860 10.42950, 105.54950 ...
1 BàRịa-VũngTàu MULTIPOLYGON (((107.09010 10.32400, 107.08890 ...
2 BắcGiang MULTIPOLYGON (((106.28380 21.13230, 106.27340 ...
3 BắcKạn MULTIPOLYGON (((105.87240 21.85580, 105.86290 ...
4 BạcLiêu MULTIPOLYGON (((105.42440 9.02130, 105.41640 9...
... ... ...
58 TràVinh MULTIPOLYGON (((106.41350 9.52920, 106.40880 9...
59 TuyênQuang MULTIPOLYGON (((105.51040 21.60470, 105.51410 ...
60 VĩnhLong MULTIPOLYGON (((106.06320 9.94750, 106.06270 9...
61 VĩnhPhúc MULTIPOLYGON (((105.57130 21.16150, 105.53360 ...
62 YênBái MULTIPOLYGON (((104.79460 21.33520, 104.79080 ...
Dữ liệu PM 2.5 có sẵn
Ở đây chúng ta sẽ sử dụng dữ liệu của bài báo khoa học này
Aaron van Donkelaar, Melanie S. Hammer, Liam Bindle, Michael Brauer, Jeffery R. Brook, Michael J. Garay, N. Christina Hsu, Olga V. Kalashnikova, Ralph A. Kahn, Colin Lee, Robert C. Levy, Alexei Lyapustin, Andrew M. Sayer and Randall V. Martin (2021). Monthly Global Estimates of Fine Particulate Matter and Their Uncertainty Environmental Science & Technology, 2021, doi:10.1021/acs.est.1c05309. [Link]
Các bạn có thể truy cập để lấy dữ liệu từ đây (toàn cầu, từ 1998 – 2022)
Chúng ta sẽ lấy dữ liệu với độ nét cao nhất.
Annual and monthly mean PM2.5 [ug/m3] at 0.01° × 0.01°
Để lấy ví dụ, chúng ta sẽ thử xem nồng độ PM 2.5 trung bình năm 2018 ở Việt Nam.
B1: Đọc data
Vì Việt Nam ở châu Á nên chúng ta chỉ cần lấy dữ liệu của Asia là được. Sau khi tải về, các bạn sẽ có 1 file có đuôi .nc. Để đọc file này, các bạn cần package netCDF4 của Python.
from scipy.io import netcdf
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from netCDF4 import Dataset
from numpy import dtype
import pandas as pd
# open a netCDF file to read
filename = "V5GL04.HybridPM25.Asia.201801-201812.nc"
ncin = Dataset(filename, 'r', format='NETCDF4')
Nếu in ra thì file ncin này là một cái dictionary với 3 keys là lat, lon, và GWRPM25. Mình sẽ lấy chúng ra.
pm25 = ncin.variables['GWRPM25'][:]
lat = ncin.variables['lat'][:]
lon = ncin.variables['lon'][:]
Nếu các bạn check dimension bằng lệnh .shape thì sẽ thấy pm25 là một cái grid 5500 x 8000. Mỗi tổ hợp lat và lon sẽ cho ra một giá trị tương ứng. Để tiện làm việc thì đầu tiên, chúng ta sẽ dùng xarray để chuyển từ dữ liệu gốc sang dữ liệu nhiều chiều, sau đó dùng pandas để kéo dữ liệu này ra.
import xarray as xr
# Assuming you have already loaded the data into pm25, lat, and lon arrays
# Create xarray DataArray objects
pm25_da = xr.DataArray(pm25, dims=('lat', 'lon'),
coords={'lat': lat, 'lon': lon})
lat_da = xr.DataArray(lat, dims=('lat',), coords={'lat': lat})
lon_da = xr.DataArray(lon, dims=('lon',), coords={'lon': lon})
# Create an xarray Dataset
dataset = xr.Dataset({'pm25': pm25_da, 'lat': lat_da, 'lon': lon_da})
# Convert xarray Dataset to pandas DataFrame
df = dataset.to_dataframe()
# Reset index to convert MultiIndex to regular columns
df_reset = df.reset_index()
# Melt the DataFrame to long form
df_long = df_reset.melt(id_vars=['lat', 'lon'], var_name='variable', value_name='value')
Dữ liệu sau khi được kéo là df_long sẽ có 5500 x 8000 = 44,000,000 dòng.
lat lon variable value
0 -9.995000 65.004997 pm25 NaN
1 -9.995000 65.014999 pm25 NaN
2 -9.995000 65.025002 pm25 NaN
3 -9.995000 65.035004 pm25 NaN
4 -9.995000 65.044998 pm25 NaN
... ... ... ... ...
43999995 44.994999 144.955002 pm25 NaN
43999996 44.994999 144.964996 pm25 NaN
43999997 44.994999 144.975006 pm25 NaN
43999998 44.994999 144.985001 pm25 NaN
43999999 44.994999 144.994995 pm25 NaN
[44000000 rows x 4 columns]
Nhìn nhiều NaN vậy thôi yên tâm, dữ liệu này rất ổn. Các bạn có thể check có bao nhiêu Nan
# check how many missing values are in the df_long['value'] column
print(df_long['value'].isna().sum())
# check how many not misisng values
print(df_long['value'].notna().sum())
B2: Xử lý geo địa giới hành chính
Ở phần 1 chúng ta biết rằng dữ liệu địa giới hành chính được lưu vào một cái tuple. Để tiện làm việc thì mình sẽ kéo hết dữ liệu trong đó ra và tạo thành một cái DataFrame. Chúng ta sẽ loop qua từng item trong tuple, lấy dữ liệu lat và lon trong đó rồi add vào cột tương ứng trong DataFrame mới mà vẫn giữ tên của cái tỉnh/thành phố đó.
# Create a GeoDataFrame
gdf = gpd.GeoDataFrame(gdata_truc)
# Define lists to store latitudes and longitudes
lats = []
lons = []
names = [] # List to store repeated NAME_1 values
# Iterate through each row
for index, row in gdf.iterrows():
# Get the geometry
geometry = row['geometry']
name = row['NAME_1'] # Get the NAME_1 value for the row
# If it's a MultiPolygon, iterate through its constituent polygons
if geometry.geom_type == 'MultiPolygon':
for polygon in geometry.geoms:
# Extract coordinates
coords = polygon.exterior.coords
# Separate latitudes and longitudes
latitudes = [coord[1] for coord in coords]
longitudes = [coord[0] for coord in coords]
# Extend the lists
lats.extend(latitudes)
lons.extend(longitudes)
# Repeat NAME_1 for the corresponding number of coordinates
names.extend([name] * len(latitudes))
# If it's a Polygon, extract coordinates directly
elif geometry.geom_type == 'Polygon':
coords = geometry.exterior.coords
latitudes = [coord[1] for coord in coords]
longitudes = [coord[0] for coord in coords]
lats.extend(latitudes)
lons.extend(longitudes)
names.extend([name] * len(latitudes))
# Create a DataFrame for latitudes, longitudes, and repeated names
coordinates_df = pd.DataFrame(
{'NAME_1': names, 'lat': lats, 'lon': lons})
Kết quả chúng ta sẽ có một cái DataFrame như sau:
NAME_1 lat lon
0 AnGiang 10.4295 105.5486
1 AnGiang 10.4252 105.5495
2 AnGiang 10.4205 105.5465
3 AnGiang 10.4188 105.5523
4 AnGiang 10.4165 105.5522
... ... ... ...
42578 YênBái 21.3381 104.8191
42579 YênBái 21.3340 104.8151
42580 YênBái 21.3337 104.8078
42581 YênBái 21.3307 104.8022
42582 YênBái 21.3352 104.7946
[42583 rows x 3 columns]
B3: Match 2 datasets
Nhiều khi do độ phân giải khác nhau, hoặc dữ liệu PM 2.5 bị bỏ trống cho 1 ô nào đó, nên cách tốt nhất mình nghĩ là chúng ta sẽ không nên match chính xác dữ liệu ở B1 và B2. Thay vào đó, chúng ta sẽ match tương đối và lấy mean. Để làm được điều đó, đầu tiên mình sẽ lấy các giá trị min và max của kinh vĩ độ từng tỉnh.
# return the unique values in the NAME_1 column
unique_names = coordinates_df['NAME_1'].unique()
# loop through the unique names, return the max and min values of the lat and lon columns
# and save them in a new DataFrame
# Create an empty list to store the results
results = []
# Iterate through the unique names
for name in unique_names:
# Get the subset of the DataFrame for the current name
subset = coordinates_df[coordinates_df['NAME_1'] == name]
# Get the maximum and minimum latitudes and longitudes
max_lat = subset['lat'].max()
min_lat = subset['lat'].min()
max_lon = subset['lon'].max()
min_lon = subset['lon'].min()
# Append the results as a dictionary to the list
results.append({'NAME_1': name, 'max_lat': max_lat, 'min_lat': min_lat,
'max_lon': max_lon, 'min_lon': min_lon})
# Convert the list of dictionaries to a DataFrame
results_df = pd.DataFrame(results)
Các bạn sẽ thu được một cái DataFrame như sau. Như vậy, chúng ta coi mỗi tỉnh/thành phố là một ô vuông.
NAME_1 max_lat min_lat max_lon min_lon
0 AnGiang 10.9621 10.1836 105.5753 104.7784
1 BàRịa-VũngTàu 10.8045 10.3203 107.5714 106.9962
2 BắcGiang 21.6263 21.1216 107.0336 105.8808
3 BắcKạn 22.7412 21.8045 106.2471 105.4311
4 BạcLiêu 9.6374 9.0172 105.8605 105.2326
.. ... ... ... ... ...
58 TràVinh 10.0811 9.5292 106.6124 105.9525
59 TuyênQuang 22.6978 21.4976 105.5987 104.8490
60 VĩnhLong 10.3312 9.8838 106.2897 105.6823
61 VĩnhPhúc 21.5738 21.1542 105.7861 105.3225
62 YênBái 22.2919 21.3259 105.1003 103.8860
[63 rows x 5 columns]
Bây giờ, chúng ta có thể coi dữ liệu PM2.5 ở B2 như những ô vuông nhỏ hơn. Chúng ta sẽ tổng hợp các giá trị PM2.5 ở các ô vuông nhỏ và lấy mean để ra giá trị cho ô vuông lớn.
# Create an empty list to store the results
final_results = []
# Iterate through the rows of the results DataFrame
for index, row in results_df.iterrows():
# Get the name, max_lat, min_lat, max_lon, and min_lon values
name = row['NAME_1']
max_lat = row['max_lat']
min_lat = row['min_lat']
max_lon = row['max_lon']
min_lon = row['min_lon']
# Get the subset of the DataFrame for the current name
subset = df_long[(df_long['lat'] <= max_lat) & (df_long['lat'] >= min_lat) &
(df_long['lon'] <= max_lon) & (df_long['lon'] >= min_lon)]
# Calculate the mean of the non-empty values in the 'value' column
mean_value = subset['value'].mean()
# Append the results as a dictionary to the list
final_results.append({'NAME_1': name, 'mean_pm25': mean_value})
# Convert the list of dictionaries to a DataFrame
final_results_df = pd.DataFrame(final_results)
Dữ liệu trả về sẽ là
NAME_1 mean_pm25
0 AnGiang 21.447590
1 BàRịa-VũngTàu 18.311316
2 BắcGiang 28.892191
3 BắcKạn 29.378609
4 BạcLiêu 20.359976
... ... ...
58 TràVinh 19.409878
59 TuyênQuang 32.422844
60 VĩnhLong 21.321384
61 VĩnhPhúc 36.816364
62 YênBái 32.511963
Bây giờ các bạn merge dữ liệu này với các geodata gốc ở bước 1 là xong.
gdata_pm = gdata.merge(final_results_df, on='NAME_1')
Sau đó, chúng ta có thể plot để xem nó như thế nào.
# plot the mean_pm25 values on the map
gdata_pm.plot(column='mean_pm25', legend=True, figsize=(15, 10))
# Add a title
plt.title('Mean PM2.5 Concentration in Vietnam 2018')
# Show the plot
plt.show()
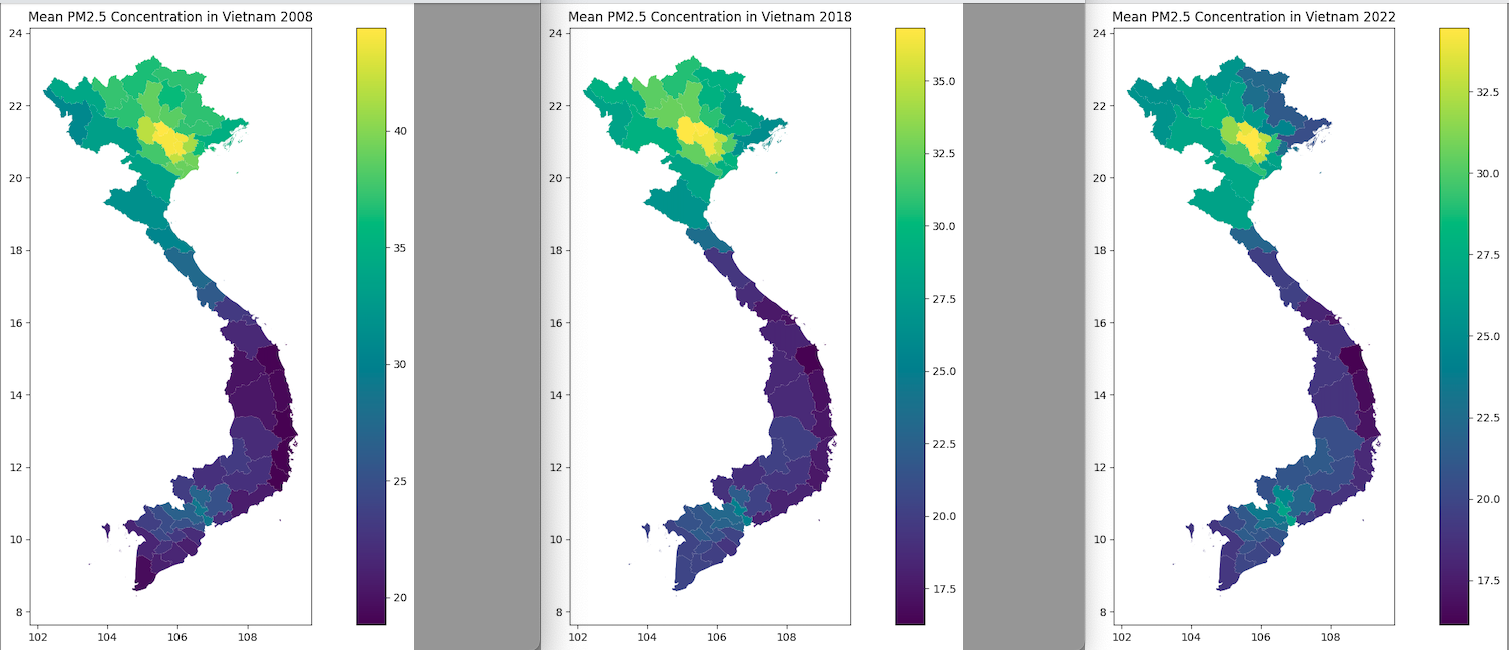
Ở đây mình lấy dữ liệu các năm 2008, 2018 và 2022. Nói chung chất lượng không khí ở VN luôn vượt mức cho phép của WHO (là không quá 5 µ/m3 một năm) nhưng có xu hướng giảm. Nơi ô nhiễm nặng nhất vẫn là Hà Nội và khu vực phía Bắc.
Tự ước lượng PM2.5
Để ước lượng công thức PM2.5 thì các bạn cần các chỉ số về Black Carbon, SO4, Dust, v.v.. Công thức được dựa vào bài báo khoa học sau:
Buchard V, Randles CA, da Silva AM, Darmenov A, Colarco PR, Govindaraju R, Ferrare R, Hair J, Beyersdorf AJ, Ziemba LD, Yu H. The MERRA-2 Aerosol Reanalysis, 1980 Onward. Part II: Evaluation and Case Studies. J Clim. 2017 Sep 1;30(17):6851-6872. doi: 10.1175/jcli-d-16-0613.1. Epub 2017 Jul 27. PMID: 32908329; PMCID: PMC7477811.
pm25 = (ds['BCSMASS'] + ds['OCSMASS'] + (ds['SO4SMASS'] * 1.375) + ds['DUSMASS25'] + ds['SSSMASS25'])*1e9
Đây đều là các chỉ số thu được từ dữ liệu vệ tinh của NASA mang tên MERRA-2. Dữ liệu này có tần suất theo giờ, và được thu thập liên tục từ năm 1980 cho tới nay. Trong khuôn khổ bài viết này, mình sẽ không đi sâu thêm bởi vì dữ liệu này rất đồ sộ và muốn lấy được dữ liệu thì cần đăng ký với hệ thống của NASA (free account).
Để có thể scrape được dữ liệu thì các bạn cần biết toạ độ lat và lon của các tỉnh/thành phố trung ương ở Việt Nam. Toạ độ CENTROID (tức là 1 tỉnh, 1 lat 1 lon) là đủ. Hiện nay thì mình chỉ biết đến trang sau đây:
https://geokeo.com/database/state/vn
Trang này có chứa dữ liệu về lat và lon CENTROID của 63 tỉnh thành, nhưng có vẻ khá là khó scrape nên vẫn phải copy paste chay. Sau khi có được dữ liệu lat và lon đó rồi, các bạn có thể vào Github sau để lấy script.
https://github.com/emilylaiken/merradownload
Chú ý là chạy script này có thể sẽ bị lỗi ở phần cuối: đọc dữ liệu từ các file .nc và xuất chúng thành .csv. Mình đã sửa phần đó. Các bạn có thể xem ở đây.

Bài viết rất chi tiết và hữu ích, cảm ơn tác giả đã tâm huyết chia sẻ.
ThíchThích
Cảm ơn bài viết của anh ạ, anh cho e hỏi là mình có thể lập bản đồ lũ từ dữ liệu Nasa dùng python đuợc không ah?
ThíchThích
Nếu như nasa có dữ liệu đó thì chắc chắn làm được nhé.
ThíchThích
Tham khảo: https://www.earthdata.nasa.gov/learn/pathfinders/disasters/floods-data-pathfinder/find-data
ThíchThích